요즘 EKS를 사용하고 있는 회사들이라면 Karpenter에 대해서 한번씩은 들어봤을 것이다.
Karpenter는 EC2를 생성 및 오토스케일링 해주는 오픈소스 서비스로 Cluster Autoscaler에 대한 단점들을 보완해준다고 많이 설명되어 있다.
Cluster Autoscaler에 비해 Karpenter가 가지는 장점 및 단점들은 다양한 매체나 블로그 글에 많이 소개가 되어 있기 때문에 Karpenter에 대한 소개는 아주 간단히 진행하고 현재 Karpenter를 어떻게 사용하고 있고 Karpenter를 사용할 때 주의 사항 및 간단한 팁들을 소개할 예정이다.
# 1. Karpenter 구성 요소
Karpenter는 크게 다음의 요소로 구성되어 있다.
- Karpenter(Pod) : 실질적으로 작업을 수행하는 역할이며, Kubernetes 관리자가 Provisioner와 NodeTemplate 등을 전달해주면 이를 기반으로 Kuberentes 상태를 체크하며 적절한 EC2를 프로비저닝하게 된다.
- Provisioner : 원하는 EC2를 프로비저닝할 수 있도록 해주는 명세서이며, 필수로 NodeTemplate를 참조해야만 한다.

- Node Template : AWS 관련된 설정을 명세한다. 여기서는 userData 혹은 어떤 서브넷에 배치할 것인지, 어떤 태그를 적용하며 어떤 IAM Profile을 적용할지 등을 설정할 수 있다.
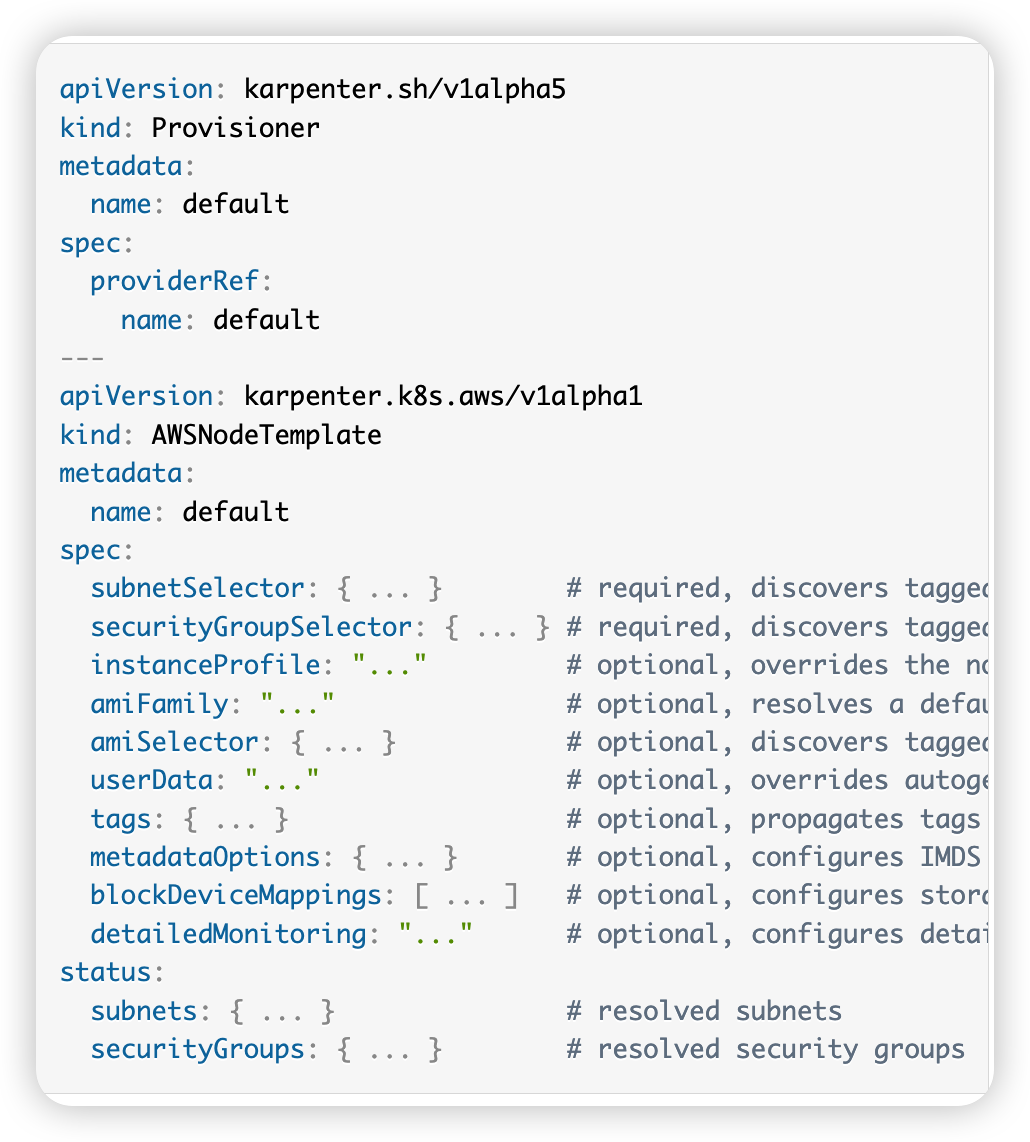
# 2. Karpenter를 어떻게 사용하고 있는지
1. 프로비저너와 노드 템플릿 세팅
개발자들에게는 Deployment 혹은 StatefulSet을 배포할 때 상호 협의한 Node Label만 적용할 수 있도록 하여 부담 요소를 덜었다.
예를 들어 아래의 Node Label을 Pod의 NodeSelector 혹은 NodeAffinity로 설정하여 원하는 타입에 대해 워크로드를 배포할 수 있도록 하였다.
role: computing
role: memory
role: general
개발계와 QA 혹은 스테이징 같은 경우에는 t 타입으로 사용하도록 하였고 운영계는 위처럼 목적에 맞게 컴퓨팅 타입 / 메모리 타입 / 범용 타입을 설정할 수 있도록 하였다.
- 참고로 spot, on-demand를 동시에 설정하면 가급적이면 Spot을 우선적으로 띄우려고 노력한다.
requirements:
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["t3.medium", "t3.large", "t3.xlarge",
"t3a.medium", "t3a.large", "t3a.xlarge"]
- key: "karpenter.k8s.aws/instance-hypervisor"
operator: In
values: ["nitro"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["ap-northeast-2a", "ap-northeast-2c"]
- key: "kubernetes.io/arch"
operator: In
values: ["amd64"]
- key: "karpenter.sh/capacity-type"
operator: In
values: ["spot", "on-demand"]
만약 여기서 Graviton을 사용한다면 Graviton 관련하여 arch를 arm64로 변경하여 Provisioner 이름을 computing-graviton 이런식으로 단어 하나를 추가하면 사용할 수 있도록 하였으며 spot을 사용하고 싶다면 computing-graviton-spot을 사용할 수 있도록 미리 프로비저너를 정의해주었다.
이는 물론 개발자들의 편의성을 위해 만든 것이며 운영자들이 워크로드들을 배포할 때는 한개의 프로비저너를 사용했다.
여기서 t타입 혹은 r타입을 고르기 위해서는 NodeSelector 혹은 NodeAffinity에 karpenter.sh/capacity-type 등을 추가로 명시해주면 아주 깔끔하게 원하는대로 배포할 수 있었다.
(이러한 방법을 개발자들에게 가이드하면 부하가 올 것 같아서 개발자들용 프로비저너는 어쩔수 없이 많이 만들었다.)
2. consolidation 그리고 ttlSecondsUntilExpired 세팅
consolidation은 노드에 Pod 리소스들이 적절히 배치되었는지 모니터링하여 효율적으로 리소스 배치가 되어 있지 않은 노드는 Cordon , Drain 하여 다른 노드로 파드들을 배치할 수 있도록 하는 비용 최적화 옵션이다.
결론을 먼저 말하자면 개발, QA, Stage는 앵간하면 consolidation: true 옵션을 넣어주고 ttlSecondsUntilExpired 옵션도 넣어주었다.
하지만 운영계는 최대한 안정적으로 파드들이 운영되어야 하기 때문에 옵션을 넣어주지 않았으며 ttlSecondsAfterEmpty로 대체하였다.
그리고 Spot Workload에서 consolidation이 예상한대로 동작되지 않았다.
예를 들어 Node에 Pod가 1대밖에 없는데 다른 노드로 이사를 시키지 않는 현상도 존재하였는데, 아래의 Github Issue에서 그에 대한 이유를 알 수 있었는데, 스팟 -> 스팟 간 Consolidation이 생각외로 간단하지 않다는 것이었다.
스팟 인스턴스를 쓰면 어느정도 감수를 해야 하지 않을까 싶기도 하다.
https://github.com/aws/karpenter/issues/2741
Spot -> Spot Consolidation · Issue #2741 · aws/karpenter
Tell us about your request originally discussed in #1091, but when the conversation started to be fruitful "aws locked as resolved and limited conversation to collaborators" Tell us about the probl...
github.com
그래서 비효율적으로 리소스가 점유되고 있는 노드의 경우 2주마다 한번씩 수동 Cordon, Drain을 수행하기로 하였다.
3. Spot 인스턴스는 어떻게 사용하고 있는지?
Spot Instance에 대한 처리를 Karpenter에서는 기본적으로 지원하고 있다.
Karpenter에서는 Spot Instance에 대한 알람을 SQS Queue를 컨슈밍함으로써 처리하게 된다.
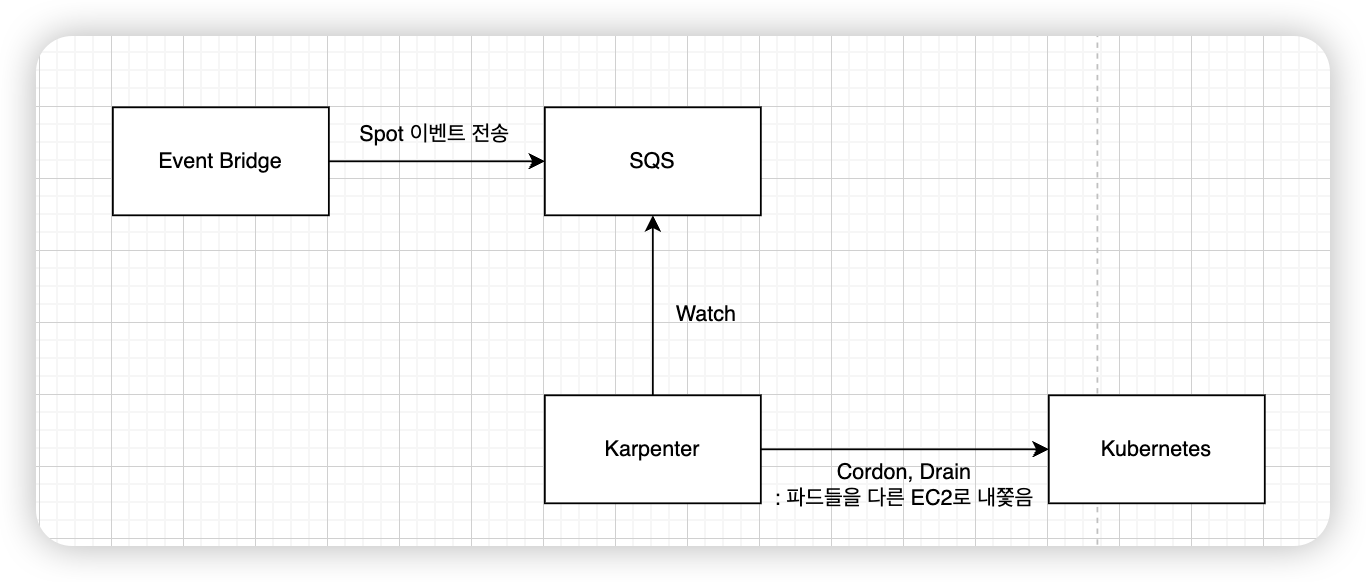
EventBridge에서 SQS로 Rebalance Recommendation, Interruption Warning에 대한 이벤트를 전송해주고 Karpenter는 이를 감시하고 있다가 처리하게 된다.
꼭 알아야 할 사항이 한가지 존재하는데 'Interruption Warning'에 대한 지원만 하고 'Rebalance Recommendation'에 대한 지원은 하지 않는다. 만약 'Rebalance Recommendation'으로도 Spot Instance를 처리해야 한다면 'Node Termination Handler'를 도입하고 Karpenter에 대한 SQS Queue는 제거해야 한다.

참고로 Node Termination Handler도 테스트를 해봤는데 잘 동작한다. 필요한 분들은 적용해서 테스트해볼 것 !
---
* Spot Instance를 처리하는 방식에 대한 개념
Rebalance Recommendation (재조정 권장) : 중단될 위험이 높은 EC2임을 알려주는 알람 (중단 위험이 높음을 알려줌)
-> 중단될 위험이 높은 EC2임을 알려주는 알람이기 때문에 상대적으로 빈도가 높음
Interruption Warning (인터럽션 경고) : 중단될 예정이므로 2분 전에 경고해주는 알람 (중단 공지)
-> 실제로 중단될 EC2인 것만 알려주기 때문에 상대적으로 빈도가 낮음
---
Alpha나 Dev, QA, Staging 환경일 경우 Spot을 큰 무리 없이 사용할 수 있지만 Production에서도 Spot을 사용해야 한다면 다양한 고려 사항들이 존재하게 된다. 대충 생각나는 것들을 정리해본다.
물론 지식이 부족하여 아래정도의 내용들만 정리했는데 추가적으로 고려해야 할 것들이 있다면 알려주세요.
- GracefulShutdown이 설정되어 있는지?
(1) Application에 대한 GracefulShutdown이 정의되어 있는지? 만약 Application에 대한 GracefulShutdown 지원을 안한다면 Hook을 통해 처리되도록 하였는지?
(2) Istio를 사용하고 있다면 Istio Proxy에 대한 GracefulShutdown 또한 설정을 하였는지?
(3) 응답시간이 오래 걸리는 서비스가 있는지? 만약 응답시간이 오래 걸리는 서비스가 Spot 이벤트로 인해 Cordon, Drain을 수행하게 되었는데 GracefulShutdown 내에 처리가 되지 못한다면 어떻게 될 것인지?
(4) Deployment 파드가 2개 이상 떠있는데 2개의 노드가 한꺼번에 Spot 이벤트가 발생한다면? 이에 대한 대응책으로 PDB가 잘 적용되어 있는지? Pod 기동시간까지 2분 넘게 소요되는지?
(5) PodAntiAffinity가 동일 디플로이먼트들에 대해 잘 적용되어 있는지
(6) Pod Pending 시간을 최소화하기 위해 OverProvisioning을 설정하였는지

여기서 Pod 기동 시간까지 2분이 넘게 소요된다면 Pod 기동 시간을 줄일 수 있도록 CPU에 대한 Limit 값을 좀 완화해주던가 하는 작업이 필요할 것 같고 NTH를 사용하여 Rebalance Recommendation 이벤트 또한 처리할 수 있도록 하는 작업이 필요할 수도 있다.
또한 애플리케이션에 대한 최적화를 진행하여 응답시간이 오래 걸리는, Long Connection 같은 것들을 모두 개선할 수 있는 방안도 검토해야 한다.
그리고 추가로 운영계 Spot을 적용함과 동시에 최소 1대는 OnDemand를 띄우는 방법도 고려해볼 수 있다. 2가지 방법이 존재한다.
방법 1) 온디맨드/스팟 비율 분할
https://karpenter.sh/preview/concepts/scheduling/#on-demandspot-ratio-split
Scheduling
Learn about scheduling workloads with Karpenter
karpenter.sh
방법 2) OnDmand Deployment 1대와 Spot Deployment 1개로 운영
하지만 Karpenter 컨트리뷰터의 말로는 방법 1은 Nice 한 방법이 아니라고 하며, 내 생각에도 그래보였기 때문에 굳이 테스트를 진행하지 않았다.
방법 2도 관리 포인트가 너무 많아진다는 단점이 존재하여 고려하지 않았다.
4. Karpenter에 대한 모니터링은 어떻게 하고 있는지?
대부분의 오픈소스들은 Prometheus metric을 제공한다. 따라서 Karpenter 또한 Prometheus Metric을 Prometheus로부터 Scrape 하여 Grafana에서 대시보드로 활용하여 모니터링을 수행하고 있다.
https://karpenter.sh/preview/concepts/metrics/
Metrics
Inspect Karpenter Metrics
karpenter.sh
또한 Loki로 Log들을 수집하고 있는데 이에 따른 로그 패턴들을 분석하여 대시보드화도 하였으며 Error나 Pod 재기동같은 일들이 발생할 경우 Grafana managed Alert를 통해 Slack으로 알람도 받고 있다.
GitHub - aws/karpenter: Karpenter is a Kubernetes Node Autoscaler built for flexibility, performance, and simplicity.
Karpenter is a Kubernetes Node Autoscaler built for flexibility, performance, and simplicity. - GitHub - aws/karpenter: Karpenter is a Kubernetes Node Autoscaler built for flexibility, performance,...
github.com
# 3. Karpenter 사용 간 트러블슈팅 (?)
가장 최근에 겪었던 일을 소개해보고자 한다.
아직 Beta 단계이기 때문에 철저한 모니터링 및 다양한 가설을 세우고 테스트를 해보는게 중요하다.
최근에 발생했던 이슈로는 PodTopologyConstraint를 Zone 별로 설정했을 때 'DoNotSchedule' 옵션을 넣으면 Pod가 무한 Pending이 걸리는 이슈가 있었다.
예를 들어 Pod를 7개 띄우는데 Provisioner의 Zone이 2개만 설정되어 있다고 가정해보자. 이럴때 2개의 파드만 뜨고 3개부터는 무한 Pending이 걸려서 파드가 제대로 뜨지 않는 것이었다.
그렇다고 ScheduleAnyway 옵션을 넣게 되면 Soft 옵션이라서 AZ 별로 파드를 띄우도록 하는데 보장할 수 없는 노릇이었다.
이에 대한 이유로는 Cluster AZ와 Karpenter Provisioner AZ가 달랐기 때문이다.
EKS Cluster를 생성할 때 AZ를 선택할 수 있는데 여기서 A, B, C 존을 선택했다고 가정해보자.
그리고 Karpenter Provisioner에는 2개의 AZ만 사용하기 위해 A, C 존을 명시했다고 가정해보자.
- key: "topology.kubernetes.io/zone"
operator: In
values: ["ap-northeast-2a", "ap-northeast-2c"]
여기서 Nginx 앱을 배포할 때 토폴로지 제약 조건으로 zone을 명시해주면 파드는 A, C 존까지 뜨는데는 성공한다.
topologySpreadConstraints:
- maxSkew: 1
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: nginx
하지만 클러스터에는 B존도 명시되어 있는데 Provisioner는 B존에 배포할 수 없는 노릇이며, 토폴로지 제약 조건에 DoNotSchedule을 설정해주었기 때문에 절대로 파드가 뜰 수 없는 상황이 오게 된다.
이런 경우에는 NodeAffinity 조건에 Provisioner에 명시한 Zone과 맞춰주면 해당 존에만 뜰 수 있기 때문에 해결이 된다.
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- "ap-northeast-2a"
- "ap-northeast-2c"
이후에 파드를 20개, 21개까지 늘려보고 2개까지 줄여봤을 때 각 AZ에도 적절히 분산되는 것을 확인할 수 있었다.
그 외 여러가지로 사소한 이슈나 버그 또한 존재할 수 있다.
따라서 다양한 가설을 세우고 이것저것 다양하게 테스트를 해보는게 중요할 것 같다.
'AWS' 카테고리의 다른 글
| [CloudFront] CloudFront Functions를 통해 간단히 인증 처리하기 (0) | 2023.09.25 |
|---|---|
| [CloudFront] S3 Object 변경 시 Cloudfront Invalidation 자동으로 수행하기 (0) | 2023.08.12 |
| [EKS] CoreDNS 운영 시 소소한 팁 (Rcode, ndots) (0) | 2022.11.11 |
| [Istio] EKS 환경에서 Istio로 여러개의 ALB, NLB 모두 사용하기 (0) | 2022.09.17 |
| [EKS 애드온 #2] Cluster Autoscaler Helm으로 설치하기 (0) | 2022.08.27 |



