1. 개요
필자의 경우 Grafana Tempo를 사용하고 있다.
Grafana Tempo의 경우 Metrics Generator를 통해 RED Metric을 생성할 것을 권장하고 있다.
Metrics-generator | Grafana Tempo documentation
Open source Metrics-generator Metrics-generator is an optional Tempo component that derives metrics from ingested traces. If present, the distributor will write received spans to both the ingester and the metrics-generator. The metrics-generator processes
grafana.com
하지만 이 방식에는 치명적인 단점이 존재한다.
바로 RED(Request, Error, Duration) 메트릭을 생성하기 위해 모든 Trace Data를 Grafana Tempo로 보내야 한다는 것이다.
- RED Metric을 생성하기 위해 모든 Trace 데이터들을 Tempo로 보내야 한다.
- 이 중 대부분의 데이터는 실제로 Tempo에서 검색하지 않지만 Tempo의 Metrics Generator를 위해 저장되어야 하는 데이터들이다.
>> 초당 요청률이 얼마인지, 응답시간은 어떻게 되는지, 에러는 얼마나 발생하는지 등
그럼 RED Metric을 완전히 생성하면서 샘플링 정책을 잘 적용하기 위해서 어떻게 해야 할까?
- Opentelemetry Collector의 Spanmetrics Collector 사용한다.
>> Tempo의 Metrics Generator를 버릴 수 있다.
>> Metrics Generator를 사용하지 않아도 되기 때문에 정말 필요한 Trace에 대해서만 샘플링 정책을 적용할 수 있다.
>> 불필요한 Trace를 저장하지 않기 때문에 저장소 비용 감소, 네트워크 트래픽 비용 감소, 쿼리 속도 향상 등 다양한 곳에서 이점을 가져갈 수 있다.
위와 같이 변경하게 되면 Grafana Tempo에서도 같이 검색 속도가 빨라지는 이유는 무엇인가?
(물론 Tempo 뿐만 아니라 ElasticAPM 등 기타 APM 저장소에도 해당되는 이야기일것이다.)
Trace 스키마는 일반적으로 TraceID와 TraceDuration, 그리고 Trace에 대해 Span 정보, 속성, Duration(Span #1, Span #2, ..)으로 이루어져 있다.
다음의 TraceQL문을 통해 검색한다고 가정해보자..
{resource.service.name="my-service-prod" && status: error && span.http.target="/api/v1/coupon"}
Grafana Tempo는 Parquet 포맷으로 데이터를 저장한다..
각 컬럼(traceID, Duration, Span IDs, name, Service Name, Tags(span 속성, Resource 속성), events, ..)에 해당하는 데이터를 모두 fetch 해온 뒤 Iterate(반복)하여 원하는 데이터인지 Matching 한 뒤 결과값을 반환하게 된다.
즉 데이터 양에 따라 쿼리 속도도 차이나게 되므로 데이터 양을 절대적으로 줄이면 쿼리 속도 또한 개선되게 된다고 보면 된다.
2. 구성도
아쉽지만 1개의 Opentelemetry Collector로 구성은 힘들다고 본다.
아래의 사진처럼 2 Layer로 Opentelemetry Collector로 구성되어야 한다.
- Layer 1
: Load Balancing Exporter
- Layer 2
: Spanmetrics Connector
: Tailsampling Processor
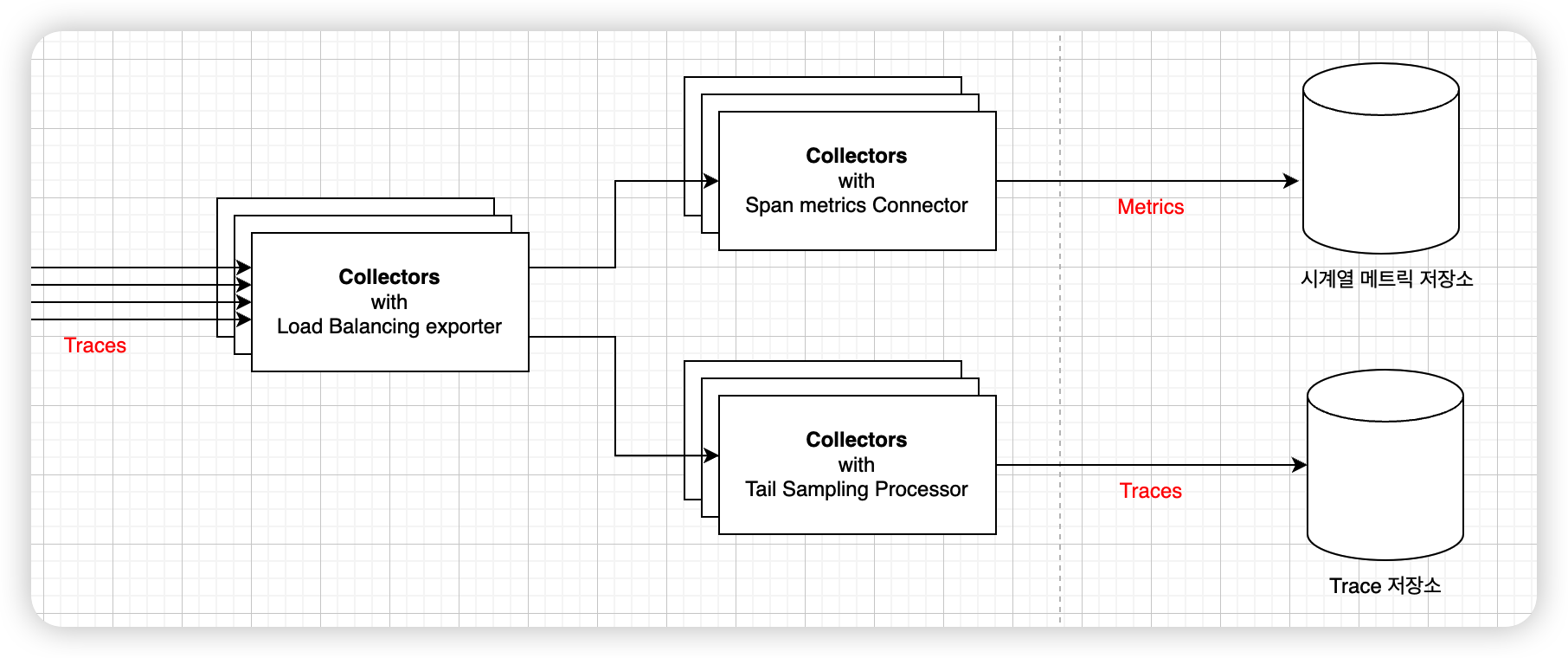
- Load Balancing Exporter가 필요한 이유는 무엇인가?
일반적으로 고가용성을 위해 Collector 인스턴스를 2대 이상 구성하게 되며 2대 이상 구성하게 되면 동일한 TraceID에 대한 Span이 각 Collector 인스턴스에 분산된다.
TailSampling Processor가 잘 동작되기 위해서는 동일한 TraceID에 대한 Span들이 동일한 Collector 인스턴스로 전달된 뒤 평가되어야 한다.
# 예시
error 트레이스에 대해서만 샘플링하고 싶은데 A Collector에는 Error 스팬이 전달되었고 B Collector에는 Error 스팬이 전달되지 않았다면 A Collector로 들어온 Span은 샘플링되지 않고 B Collector로 들어온 Span만 샘플링되는 현상
- n대의 각기 다른 Load Balancing Exporter들이 무엇을 기준으로 뒷단의 Opentelemetry Collector로 Span들을 전달하는지?
>> Spanmetrics Connector는 ServiceID를 기준으로 라우팅된다.
>> TailSampling Processor는 TraceID를 기준으로 라우팅된다.

- Load Balancing Exporter는 어떻게 뒷단의 동일한 Opentelemetry Collector Instance로 전달하는지?
Consistent 해시 알고리즘을 통해 동일한 Opentelemetry Collector instance로 전달할 수 있다.
3. 예시 설정
일반적인 Trace 검색 케이스와 이에 따른 샘플링을 어떻게 할지 살펴보자.
1. 정상 동작되는 API 지만 어떤 Span들로 구성되는지 확인
>> 모든 Trace를 저장할 필요 없이 n%의 Trace만 샘플링
2. 특정 Span의 Duration이 n초 이상 혹은 TraceDuration이 m초 이상에 대해 확인
>> 샘플링
3. Error가 발생한 경우
>> 샘플링
4. (특정 서비스는) 무조건 샘플링 하고 싶다.
>> 샘플링 정책 맨 앞에 특정 ServiceName에 대해서는 무조건 샘플링하기로 한다.
3.1. Layer 1 ) LoadBalancing Collector 설정
해당 Collector에서는 다음의 설정들을 적용해준다.
1. groupbytrace 프로세서로 들어오는 span들을 trace 단위로 그룹핑해준다.
wait_duration으로 얼마나 기다릴 것인지 정의한다.
num_traces로 해당 processor가 내부 스토리지(ex. 메모리)에 최대로 얼마나 많은 trace를 저장할 것인지 정의한다.
2. 애초에 불필요한 데이터들은 뒷단으로 보내기전에 거름
3. routing key(traceID, serviceName)을 기준으로 하여 뒷단으로 보내기
config:
receivers:
otlp:
protocols:
grpc:
endpoint: ${env:MY_POD_IP}:4317
http:
endpoint: ${env:MY_POD_IP}:4318
processors:
batch: {}
memory_limiter:
check_interval: 5s
limit_percentage: 80
spike_limit_percentage: 30
groupbytrace:
wait_duration: 5s
num_traces: 1000
## 속성 값의 길이를 제한합니다. (ex. SQL Query)
transform:
error_mode: ignore
trace_statements:
- context: resource
statements:
- truncate_all(attributes, 300)
- context: span
statements:
- truncate_all(attributes, 300)
## 디버깅에 불필요한 span 속성은 애초에 제거합니다.
attributes:
actions:
- key: thread.name
action: delete
...
...
- key: messaging.kafka.message_offset
action: delete
## 디버깅에 불필요한 resource 속성은 애초에 제거합니다.
resource:
attributes:
- key: process.command_args
action: delete
...
...
- key: telemetry.sdk.version
action: delete
## 헬스체크성 트래픽들은 애초에 제거합니다.
tail_sampling/drop_unneeded_traces:
decision_wait: 1s
expected_new_traces_per_sec: 0
policies:
- name: drop_noisy_url
type: string_attribute
string_attribute:
key: http.target
values:
- \/metrics
- \/actuator*
- opentelemetry\.proto
- \/health
enabled_regex_matching: true
invert_match: true
exporters:
## tailsampling : traceID 기준으로 라우팅
loadbalancing/tailsampling:
routing_key: "traceID"
protocol:
otlp:
timeout: 1s
tls:
insecure: true
resolver:
k8s:
service: {{tailsampling collector의 주소}}
ports:
- 4317
## spanmetrics : service name 기준으로 라우팅
loadbalancing/spanmetrics:
routing_key: "service"
protocol:
otlp:
timeout: 1s
tls:
insecure: true
resolver:
k8s:
service: {{spanmetrics collector의 주소}}
ports:
- 4317
extensions:
health_check:
endpoint: ${env:MY_POD_IP}:13133
memory_ballast:
size_in_percentage: 40
service:
extensions:
- health_check
- memory_ballast
pipelines:
############################
#### TRACE LOAD BALANCING
############################
traces:
receivers:
- otlp
processors:
- groupbytrace
- transform
- attributes
- resource
- tail_sampling/drop_unneeded_traces
- memory_limiter
- batch
exporters:
- loadbalancing/spanmetrics
- loadbalancing/tailsampling
3.2. Layer 2 ) SpanMetrics Collector 설정
해당 Collector에서는 다음의 설정들을 적용해준다.
1. connector에서는 우선 1) OTLP 엔드포인트로 Trace를 전달받고 Spanmetrics connector를 통해 trace와 metric을 연결시킨다.
>> spanmetrics에서는 exemplars 데이터를 보낼 것인지, histogram은 어떻게 설정할 것인지, dimension(추가 레이블)은 무엇무엇을 설정할 것인지 등을 정할 수 있다.
>> resource_metrics_key_attributes 설정은 필수로 해주자.
(Counter가 초기화되는 버그를 막아줄 수 있다고 한다. 자세한건 github issue 어딘가를 찾아보자..)
>> exemplars에서는 max_per_data_point를 설정 안해주니 memory leak이 발생하는 것으로 보여서 설정해주었다. 자세한건 깊게 파보질 않아서 모른다..
2. 그 후, metric - transform 부분에서 불필요한 SPAN_KIND는 필터링해버린다.
>> 필자의 경우 CLIENT, INTERNAL 메트릭은 필터링했지만 필요할 경우 필터링하지 않을 수도 있고 PRODUCER나 CONSUMER를 추가로 필터링할 수도 있고 이는 원하는대로 설정하면 된다.
3. 최종적으로 시계열 저장소로 remoteWrite 한다.
config:
receivers:
otlp:
protocols:
grpc:
endpoint: ${env:MY_POD_IP}:4317
http:
endpoint: ${env:MY_POD_IP}:4318
processors:
batch: {}
memory_limiter:
check_interval: 2s
limit_percentage: 70
spike_limit_percentage: 25
# SPAN_KIND : CLIENT, SERVER, INTERNAL, PRODUCER, CONSUMER
filter:
metrics:
datapoint:
- 'attributes["span.kind"] == "SPAN_KIND_CLIENT"'
- 'attributes["span.kind"] == "SPAN_KIND_INTERNAL"'
exporters:
prometheusremotewrite/spanmetrics:
endpoint: <PROMETHEUS와 같은 시계열 저장소 엔드포인트>
target_info:
enabled: true
external_labels:
추가로_원하는키: 추가로_원하는값
connectors:
# 1. SERVER Metrics
spanmetrics:
exemplars:
enabled: true
max_per_data_point: 5
histogram:
explicit:
buckets: [10ms, 50ms, 100ms, 400ms, 800ms, 1.5s, 3s, 6s, 10s, 15s, 22s, 30s, 60s]
aggregation_temporality: "AGGREGATION_TEMPORALITY_CUMULATIVE"
metrics_flush_interval: 15s
dimensions:
- name: http.method
- name: http.route
- name: http.status_code
...
events:
enabled: true
dimensions:
- name: exception.type
resource_metrics_key_attributes:
- service.name
extensions:
health_check:
endpoint: ${env:MY_POD_IP}:13133
memory_ballast:
size_in_percentage: 40
service:
extensions:
- health_check
- memory_ballast
pipelines:
#### OTLP -> SPANMETRICS ###
traces:
receivers:
- otlp
processors:
- memory_limiter
- batch
exporters:
- spanmetrics
#### KIND: SERVER, CONSUMER, PRODUCER
metrics/spanmetrics:
receivers:
- spanmetrics
processors:
- memory_limiter
- batch
- filter
exporters:
- prometheusremotewrite/spanmetrics
3.3. Layer 2 ) Tailsampling collector 설정
해당 Collector에서는 다음의 설정들을 적용해준다.
1. tail_sampling에 대한 정책이 정해지면 그대로 적용해준다.
>> 필자의 경우는 error가 있거나 latency가 1s 이상일 경우 무조건 샘플링하도록 하며 그 외에는 5% 비율로만 샘플링하도록 하였다. 이는 물론 예시 설정이기 때문에 Github README를 확인하면서 정책을 잘 적용해주면 된다.
>> decision_wait, num_traces, expected_new_traces_per_sec은 본인 환경에 맞게 적절히 정해주면 된다.
- 이 값들이 낮다면 레이턴시가 높은 Trace에 대해 Sampling Decision이 잘 적용되지 않을 수 있음을 참고할것.
- 이 값들이 높다면 memory 사용률이 높아진다는 점을 참고하자.
2. 최종적으로 샘플링한 데이터들만 TEMPO로 보낸다.
config:
receivers:
# OTLP
otlp:
protocols:
grpc:
endpoint: ${env:MY_POD_IP}:4317
http:
endpoint: ${env:MY_POD_IP}:4318
processors:
batch: {}
memory_limiter:
check_interval: 2s
limit_percentage: 70
spike_limit_percentage: 25
tail_sampling:
decision_wait: 30s
num_traces: 50000
expected_new_traces_per_sec: 1500
policies:
[
{
name: 500ms,
type: latency,
latency: {threshold_ms: 500}
},
{
name: error,
type: status_code,
status_code: { status_codes: [ERROR] }
},
{
name: 5percent,
type: probabilistic,
probabilistic: {sampling_percentage: 5}
}
]
exporters:
## Tempo로 Trace 전송
otlphttp:
endpoint: <TEMPO 에드포인트>
sending_queue:
enabled: true
queue_size: 150000
extensions:
health_check:
endpoint: ${env:MY_POD_IP}:13133
memory_ballast:
size_in_percentage: 40
service:
extensions:
- health_check
- memory_ballast
pipelines:
traces/tailsampling:
receivers:
- otlp
processors:
- tail_sampling
- memory_limiter
- batch
exporters:
- otlphttp
여기까지 간단히 Opentelemetry Collector를 통해 RED Metric을 생성하고 Trace에 대해 완벽하게 샘플링 정책을 적용하여 APM 저장소 비용 절감 및 검색 속도를 향상시키는 방법에 대해 알아보았다.
물론 여기에는 다음의 내용들이 생략되었다. 이 부분들은 구글링을 잘 해보자..
- Spanmetrics Connector에서 발생된 RED Metric을 기반으로 대시보드를 생성하거나 알람을 적용하기
- Opentelemetry Collector 자체에 대한 모니터링
>> receivers.prometheus 및 remoteWrite를 추가로 하고 그에 상응하는 대시보드 생성
- 등등...
'Log,Monitorings' 카테고리의 다른 글
| [Monitoring] Grafana Query-less (Explore Metrics, Logs, Traces, Profiles) 간단히 알아 (0) | 2024.07.21 |
|---|---|
| [Log] Grafana Loki 성능 최적화 방법 정리 (0) | 2024.04.07 |
| [Log] Grafana Loki 로그 Write 시 참고 사항 (3) | 2024.02.17 |
| [Opentelemetry] spanmetrics connector에 대해 알아보기 (2) | 2024.01.25 |
| [Monitoring] Grafana Tempo 알아보기 (3) | 2023.11.23 |



