1. 개요
CUDA MPS(Multi-Process Service)를 활용하여 GPU 리소스를 컨테이너간 Sharing 하여 활용하는 방법에 대해 알아본다.
GPU 노드의 GPU 자원을 나눠 사용하는 방법에는 크게 3가지가 존재한다.
- Time-Slicing
- MIG
- MPS
이 중 MIG는 비싼 GPU 노드에서만 사용 가능하니 패스하고 Time-Slicing, MPS만 필자는 알아보았다.
Time Slicing은 별도의 노력 없이 Nvidia-Device-Plugin의 단순한 설정만으로 쉽게 설정 및 적용이 가능하다.
하지만 GPU Memory의 격리가 없고 지속적인 Context Switching이 발생하여 Overhead가 높다는 단점이 있다.
그렇다면 이를 해결하기 위해 MPS(Multi Process Service)를 활용할 수 있을까?
MPS가 그럼 무엇인지 알아보자.
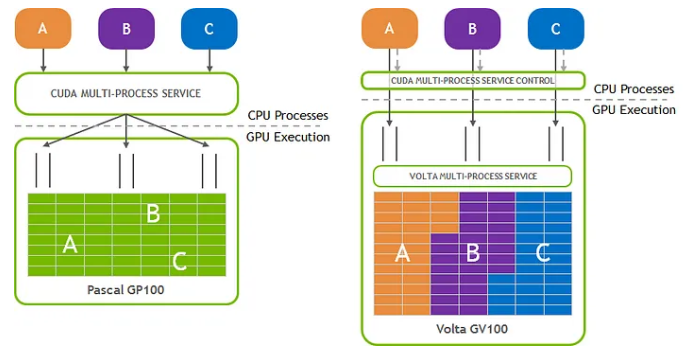
Nvidia의 MPS는 여러 컨테이너에서 노드에 연결된 단일 물리적 NVIDIA GPU 하드웨어를 공유할 수 있게 해주는 GPU Sharing 솔루션이다.
CUDA MPS는 별도의 MPS Control Server를 구동시키고 Client들로부터 Orchestration을 허용하게 되는데 장점으로는 Client 별로 메모리 리밋이 적용되며 Context Switching이 발생하지 않기 때문에 리소스를 효율적으로 사용할 수 있게 된다.
하지만 치명적인 단점으로는 Shared Context를 사용하기 때문에 심각한 에러가 발생할 경우 모든 Client에게 영향을 끼칠 수 있으므로 조심해야 한다.
2. Nvidia Device Plugin을 통해 MPS 사용하는 방법
MPS 원리를 알아보기 전에 어떻게 Nvidia Device Plugin이 MPS를 활용할 수 있도록 해주는지 알아보자.
NVIDIA Device Plugin에서는 0.15.0 버전부터 MPS를 실험적 기능으로써 제공하고 있다.
https://github.com/NVIDIA/k8s-device-plugin/releases/tag/v0.15.0
Release v0.15.0 · NVIDIA/k8s-device-plugin
The NVIDIA GPU Device Plugin v0.15.0 release includes the following major changes: Consolidated the NVIDIA GPU Device Plugin and NVIDIA GPU Feature Discovery repositories Since the NVIDIA GPU Devic...
github.com

2.1. NVIDIA Device Plugin 설치
여기서 NVIDIA Device Plugin이 하는 역할이 정확히 무엇일까?
Nvidia Device Plugin은 기 Node에 설치된 GPU Driver와 소통하며 Kubelet으로 하여금 Capacity를 변경하게끔 하는 역할을 수행한다.
[1] nvidia-device-plugin은 GPU Driver와 커뮤니케이션을 하면서 얼마나 많은 GPU를 사용할 수 있는지 확인한다.
[2] nvidia-device-plugin은 kubelet과 커뮤니케이션을 하며 node capacity를 업데이트한다.
[3] kubelet은 node capacity를 업데이트 수행한다.
[4] GPU를 사용하는 파드가 스케줄러에 의해 특정 노드에 할당된다.
[5] GPU를 사용하는 Container는 GPU를 직접 사용하게 된다.
위 과정을 거치게 되면 우리의 GPU 컨테이너들은 spec.resources 필드에 nvidia.com/gpu를 요청할 수 있게 되는 것이다.
NVIDIA Device Plugin Helm Chart에는 NFD와 GFD 또한 서브 헬름차트로써 배포할 수 있게 된다.
위 컴포넌트들에 대해서 간략하게 설명해보자면 다음과 같다.
- NFD(Node Feature Discovery) : Node에 대한 정보를 확인하여 Node Label로 업데이트해주는 컴포넌트
>> Master : Worker 들로부터 Node에 대한 정보를 전달받고 이를 실제 label로 등록해주는 역할을 수행한다.
>> Worker : 데몬셋으로 뜨며 Node에 대한 정보를 확인한 뒤 Master에게 전달해주는 역할을 수행한다.
- GFD(GPU Feature Discovery) : GPU Node에 대한 정보를 확인하여 Node label로 업데이트하기 위해 NFD Master에게 전달
1. ConfigMap
ConfigMap에는 mps에 대한 설정을 기입해주낟.
config:
# ConfigMap name if pulling from an external ConfigMap
name: ""
# Set of named configs to build an integrated ConfigMap from
map:
any: |-
version: v1
flags:
migStrategy: none
sharing:
mps:
resources:
- name: nvidia.com/gpu
replicas: 3
2. NFD, GFD 관련 설정
gfd는 daemonSet으로써 GPU Node에만 뜰 수 있도록 해준다.
nfd worker 또한 daemonSet으로써 GPU Node에만 뜰 수 있도록 해주며 nfd master는 그 외 일반 cpu를 사용하는 노드에 Deployment로써 뜰 수 있도록 해주었다.
3. 확인
배포하게 되면 다음의 파드들을 확인할 수 있게 된다.
mps control daemon 또한 daemonSet으로써 뜨게 된다.
NAME READY STATUS RESTARTS AGE
nvidia-device-plugin-5wnn7 2/2 Running 0 10m
nvidia-device-plugin-gpu-feature-discovery-9cnz7 2/2 Running 0 10m
nvidia-device-plugin-mps-control-daemon-s5ndp 2/2 Running 0 9m49s
nvidia-device-plugin-node-feature-discovery-gc-7f5956796b-lmvln 1/1 Running 0 87m
nvidia-device-plugin-node-feature-discovery-master-b56b86bwz6cr 1/1 Running 0 87m
nvidia-device-plugin-node-feature-discovery-worker-5lx47 1/1 Running 0 10m
node capicity를 확인하면 nvidia.com/gpu가 1이 아닌 3인 것을 확인할 수 있다.

nvidia-smi 명령어로 확인하면 1개의 MPS Server와 2개의 Python 서버가 뜬 것을 볼 수 있다.
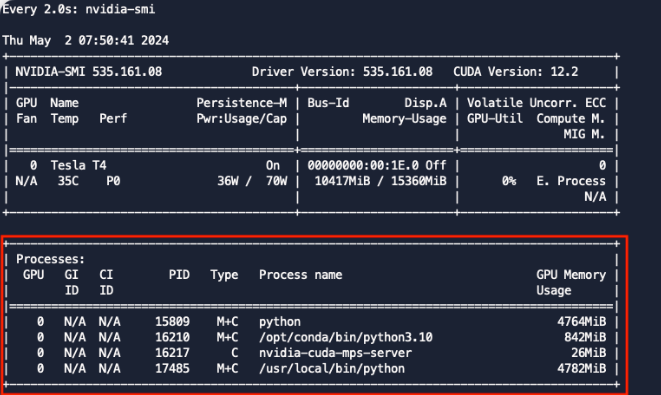
MPS Server는 /mps를 마운트하고 /mps/nvidia.com/gpu/pipe에 Client들이 통신할 수 있도록 Pipe를 생성해둔다.
Client들도 위 경로를 Mount하여 MPS Server와 통신할 수 있게 된다.
별도로 설정해주지 않아도 Nvidia Device Plugin이 알아서 위 pipe 경로를 마운트 및 환경변수 처리를 해주는 것으로 보인다.

여기까지 MPS를 활용하여 GPU 노드를 쪼개 사용하는 방법에 대해 알아보았다.
nvidia-device-plugin에서는 0.15.0 버전부터 CUDA MPS를 지원한다. 하지만 Experimental 기능인 점을 참고해야 한다.
Time Slicing과 MPS 간 성능 및 안정성에 대한 테스트를 진행해보지 않았기에 무엇이 더 낫다고 판단을 할 수 없다. 이는 실제로 여러가지 테스트를 진행해봐야 알 것 같다.
하지만 개발계에서는 충분히 MPS를 활용하여 GPU 노드를 비용 효율적으로 사용할 수 있지 않을까 생각해본다.
'AI ML' 카테고리의 다른 글
| [LLM] Prompt 엔지니어링 관련 기초 개념 정리 (3) | 2024.09.03 |
|---|---|
| Kubernetes GPU Operator와 Time Slicing 간단히 알아보기 (2) | 2024.04.07 |