1. 개요
요즘에는 대부분 Karpenter를 활용해서 EKS Node를 관리한다.
Karpenter에서는 Spot Instance를 손쉽게 활용할 수 있기 때문에 Spot Instance를 활용하는 곳들이 많을 것이다.
Spot Instance는 미사용 EC2 용량을 온디맨드 가격에 비해 최대 90% 저렴하게 사용할 수 있지만 언제든지 AWS에 의해 회수당할 수 있기 때문에 안정성이 떨어질 수 있다는 단점이 있다. 이 때 다음의 문제가 발생할 수 있다.
1. Deployment가 1대인데 파드가 떠있는 Node가 Spot Instance이기 때문에 강제로 evict 당한다면, 기존 Pod는 terminating이 되고 신규 pod는 Pending -> ContainerCreating -> Running 까지 n분이 소요될 수도 있다.
이 때 pod의 다운타임이 n분 가량 이어질 수 있다.
따라서 Spot Instance에 있는 Pod들을 안전하게 옮길 수 있도록 방안을 수립할 수 있어야 한다.
(정확하지 않은 정보를 담을 수 있으니 틀린 정보가 있다면 댓글로 알려주세요!)
2. Karpenter에서 Spot Instance를 어떻게 처리하고, Spot Instance는 어떻게 갈리는가?
그렇다면 안전하게 옮기기 위해서는 Spot Instance가 어떻게 갈리는지 알아야 한다.
Spot Instance가 갈릴 때 AWS에서는 다음의 2가지 이벤트를 사용자에게 안내해준다. 따라서 다음의 2가지 이벤트에 대해서 이해하고 있어야 한다.
# Spot Instance 발생 시 AWS에서 알려주는 이벤트 2가지
1. Rebalance Recommendation : AWS가 인스턴스 중단 위험이 높다고 판단할 때 미리 보내는 신호이며 이 신호를 받으면 새로운 스팟 인스턴스를 미리 시작하고 워크로드를 이전할 수 있음
2. Interuption Warning : 실제 인스턴스가 중단되기 2분 전에 보내는 최종 알림이며 이 시점에서는 진행 중인 작업을 빠르게 저장하고 정리해야 함
따라서 간단하게 요약하자면 Rebalance Recommendation 이벤트는 중단 위험이 높다고 판단되는 EC2를 미리 알려주는 것이고, Interuption Warning은 실제로 2분 후에 중단될 EC2를 직전에 알려주는 이벤트이다.
# Karpenter가 Spot Instance를 처리하는 방법
여기까지 Spot Instance에서 발생할 수 있는 이벤트에 대해서 알아보았고, 그럼 Karpenter가 Spot Instance에서 발생하는 Event에 대해 어떻게 처리하는지 알아보자면 다음과 같다.
1. Karpenter는 Spot Instance Event 중 Interruption Warning만 처리한다. 즉, Rebalance Recommendation 이벤트에 대해서는 무시한다.
2. Karpenter는 Interruption Warning 이벤트가 발생하면 다음의 과정으로 처리한다.
- EventBridge에서 SQS Queue로 Interruption Warning 이벤트가 발생했음을 알려준다.
- Karpenter는 SQS Queue를 바라보고 있고, 어떤 EC2가 Interruption Warning이 발생했는지 확인한다.
- Karpenter는 다음의 순서로 Spot Instance를 처리한다.
[1] 노드 Cordon
[2] 노드 Drain
[3] 노드 Delete
# cordon & drain 발생 시 pod가 어떻게 처리되는지?
그렇다면 Karpenter는 Interruption Warning 이벤트가 발생하면 Cordon, Drain만 수행한다는 것을 이해하게 되었는데 그렇다면 Cordon & Drain 발생 시 해당 노드에 떠 있는 파드들은 어떻게 처리될까?
가정)
- A Node에 Cordon & Drain을 수행한다고 가정해보자.
- A Node에 떠있는 Z Deployment는 Replicas가 1대이다.
1. A Node에 Cordon을 수행 : Cordon은 지정된 노드에 더 이상 신규 파드가 스케줄링 되지 않도록 하는 역할이다.
2. A Node에 Drain을 수행 : A Node에 떠있는 Pod들은 강제로 evict를 당한다.
(여기서 보통 Drain을 할 때는 daemonSet을 제외한다.)
3. (중요)
- Pod는 그 즉시 terminating 상태가 된다.
- terminating이 되기 때문에 Running Pod가 0ea가 되고 Desired State를 맞추기 위해 신규 Pod 1ea가 뜨려고 한다.
- 신규 Pod가 뜰 Node가 있다면 바로 ContainerCreating이 될 것이다.
- 신규 Pod가 뜰 Node가 없다면 Pending 상태가 되고 Karpenter에 의해 신규 Node가 프로비저닝되면 그 이후에 ContainerCreating -> Running 상태가 된다.
그렇다면 기본적으로 Karpenter에 의해서 Spot Instance를 처리하고 있었다면 이렇게 정리할 수 있을 것이다.
1. Reblanace Recommendation에 대해서는 아무것도 처리하지 않고 있을 것이다.
2. Interruption Warning에 대해서는 Karpenter가 처리한다. 하지만 Replicas가 1대인 Pod는 필연적으로 Downtime이 발생할 수 밖에 없다.
-> 이 때 개발자들은 아무런 이유도 모르는 상태로 개발 환경의 서비스가 'no healthy upstream' 같은 에러 문구를 n분동안 지켜볼 수 밖에 없을 것이다.
이런 배경으로 인해 Spot Instance에 배포되어 있는 Pod들을 안전하게 옮길 수 있는 방안들을 고민하게 되었으며, 다음의 과정으로 처리하게 되었다.
3. 어떻게 처리하도록 하면 좋을지?
아직 이부분에 대해서 무엇이 정답인지는 모르겟지만 필자는 아래처럼 처리하도록 했다.

우선 Spot Instance의 이벤트를 각각 나눠서 생각해야 할 것 같다.
[1] Rebalance Recommendation 이벤트가 발생할 경우
- AWS Node Termination Handler가 DaemonSets로 떠있고 Rebalance Recommendation 이벤트를 전달 받으면 Webhook을 통해 직접 띄워둔 FastAPI 서버로 전달한다.
- FastAPI 서버는 안전하게 노드를 이전할 수 있도록 신규 파드를 미리 띄워둔 뒤에 기존 파드를 종료한다.
[2] Interruption Warning 이벤트가 발생할 경우
- 기존처럼 Karpenter에 의해서 Interruption Warning 이벤트가 발생할경우 Cordon & Drain을 처리할 수 있도록 했다.
(이 때 다운타임이 발생할 수 밖에 없다. 따라서 아직 이 부분을 어떻게 처리해야 할지는 고민중이다. 하지만 최대한 Rebalance Recommendation에서 거를 수 있다면 이전보다는 좀 더 나아지지 않을까?해서 지켜보고는 있다.)
[3] (추가로) Karpenter의 Consolidation(통합)에 의해 노드가 갈릴 경우
- 해당 케이스는 Spot Instance와는 무관하지만 어쨌든 Pod의 Downtime을 야기할 수 있기 때문에 이 부분도 고려해주면 좋다.
- Consolidation이 새벽에만 처리될 수 있도록 Nodepool CR 설정을 적절히 조정하였다.
참고로, AWS Node Termination Handler를 왜 쓰냐면 Rebalance Recommendation 이벤트가 발생하면 API 서버로 알려줘야 하기 때문에 사용했다.
물론 EventBridge에서 발생하는 이벤트를 기반으로 처리해도 무방하다.
NTH에 대해서 더 알고 싶다면 아래 글을 참고할 것.
https://techblog.gccompany.co.kr/nth-nodeterminationhandler-9bc5b2af4ad7
NTH(NodeTerminationHandler)
안녕하세요. 여기어때컴퍼니 SRE팀에서 EKS(Elastic Kubernetes Service, AWS의 관리형 Kubernetes 서비스)를 담당하고 있는 젠슨입니다.
techblog.gccompany.co.kr
4. AWS Node Termination handler 설정 예시와 FastAPI 코드 일부
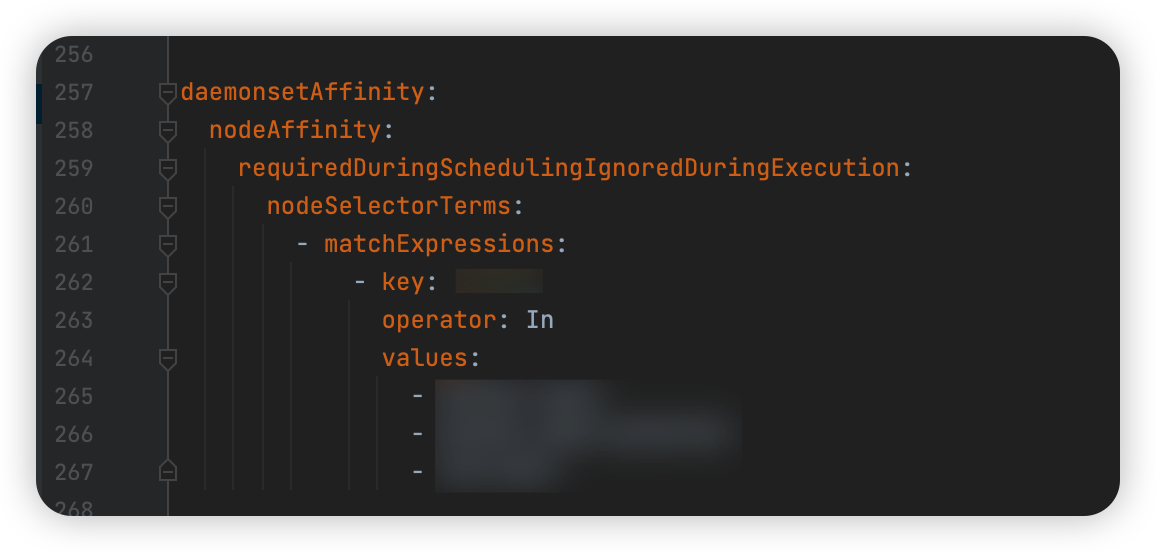
AWS NTH를 IMDS 모드로 설치해야 하기 때문에 원하는 노드에 대해서만 DaemonSets가 배포되어야 한다.
따라서 daemonsetAffinity 설정을 다음과 같이 수행해주었다.
그리고 Rebalance Recommendation 이벤트가 발생하면 Webhook을 날려줘야 하는데, Webhook 설정을 다음과 같이 해주었다.
Account나 Region, InstanceType 등은 굳이 필요없을 수도 있기 떄문에 필요없으면 NodeName만 전달해줘도 무방할 것 같다.
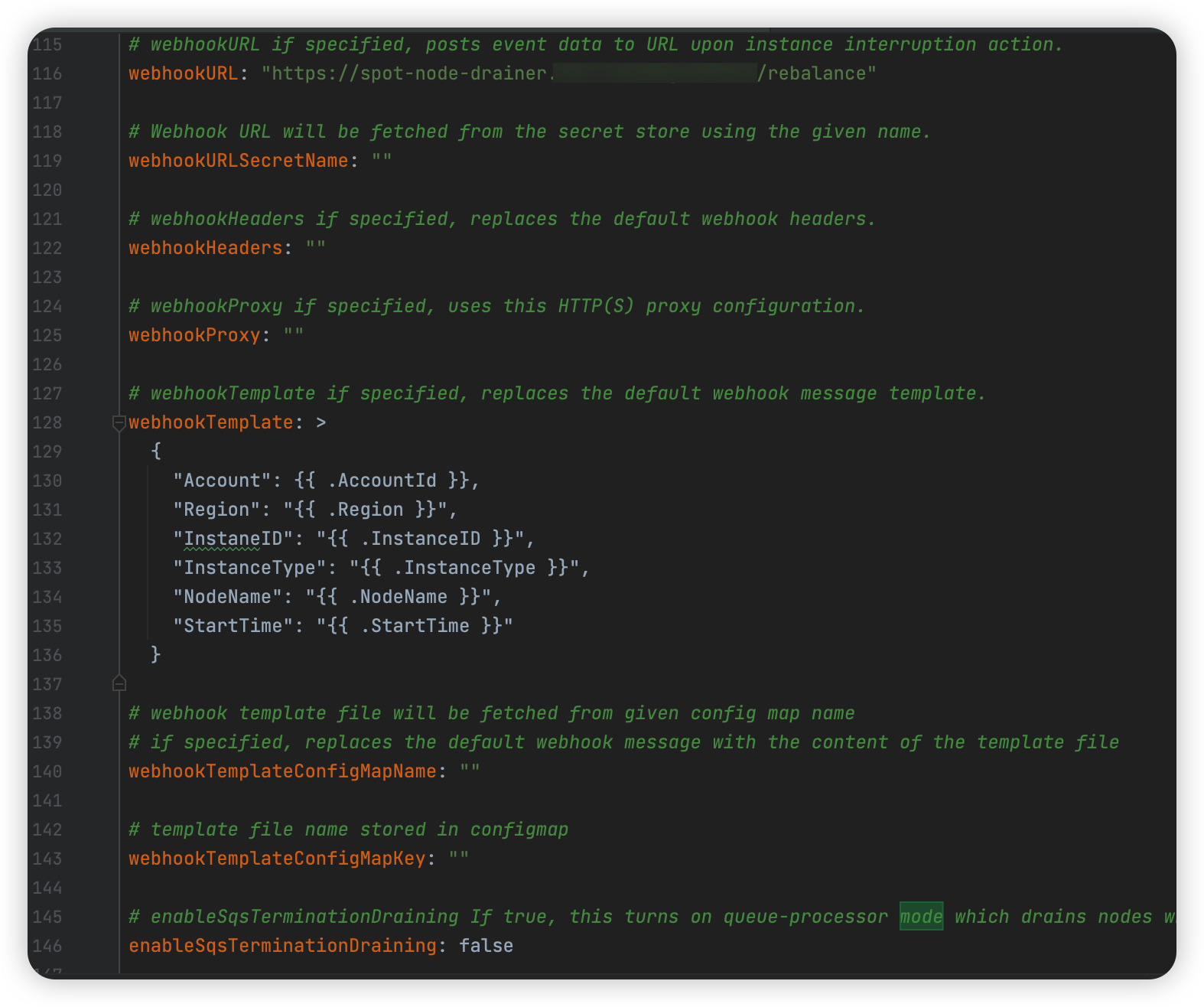
그리고 아래 설정을 통해 IMDS 모드로 동작시키겠음을 알려준다.
# enableSqsTerminationDraining If true, this turns on queue-processor mode which drains nodes when an SQS termination event is received
enableSqsTerminationDraining: false
IMDS Mode에서만 사용하는 옵션들을 적절히 조정해준다.
- enableSpotInterruptionDraining : 인터럽션 이벤트가 발생 시 Draining을 할 것인지 설정
- enableScheduledEventDraining : EC2 예정된 이벤트가 발생하면 Draining을 할 것인지 설정
- enableRebalanceMonitoring : Rebalance 이벤트가 발생 시 Cordon을 수행할 것인지 설정
- enableRebalanceDraining : Rebalance 이벤트가 발생 시 Draining을 할 것인지 설정
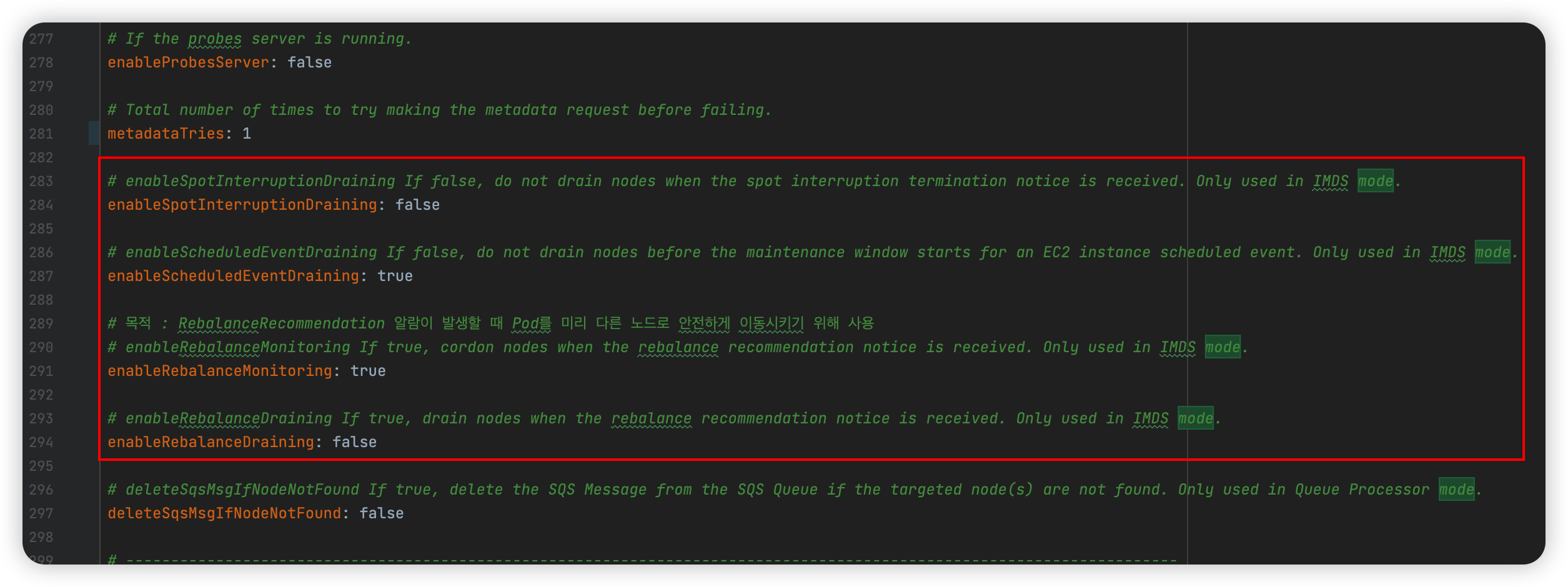
위 설정들이 완료되었다면 Rebalance 이벤트가 발생 시 webhook URL로 webhook을 발송시키는 것을 Log로 확인할 수 있게 된다.
그럼 이제 FastAPI 코드를 간단하게 살펴보자.
당연히 대충 짰기 때문에 흐름만 이해하면 될 것이다.
Main 코드
from fastapi import FastAPI
import asyncio
import logging
from src.models import RebalanceResponse
from src.k8s_operations import K8sOperations
from src.config import settings
from fastapi.responses import JSONResponse
from fastapi import Request, HTTPException
import json
# 로깅 설정
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s | %(name)s | %(levelname)s | %(message)s'
)
logger = logging.getLogger(__name__)
# App 객체 생성
app = FastAPI(title=settings.APP_NAME)
# k8s_ops 객체 생성
k8s_ops = K8sOperations()
@app.get("/")
def health_check():
return JSONResponse(
status_code=200,
content="health check passed"
)
@app.post("/rebalance", response_model=RebalanceResponse)
async def rebalance_node(request: Request):
body = await request.body()
decoded_body = body.decode('utf-8')
try:
data = json.loads(decoded_body)
except json.JSONDecodeError as e:
# JSONDecodeError 발생 시, 문제의 decoded_body와 함께 400 에러 반환
logger.error(f"Invalid JSON format: {decoded_body}, type : {type(decoded_body)}")
raise HTTPException(status_code=400, detail="Invalid JSON format") from e
# NodeName 추출
node_name = data.get("NodeName", None)
if node_name is not None:
# 백그라운드에서 rebalance task 수행
asyncio.create_task(k8s_ops.handle_rebalance(node_name))
return RebalanceResponse(
message="Rebalance process started",
node_name=node_name
)
else:
return RebalanceResponse(
message="node_name not found in request",
node_name=node_name
)
if __name__ == "__main__":
import uvicorn
uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=settings.AUTO_RELOAD)
- /rebalance로 POST 요청을 받을 경우 nodeName을 추출하여 node rebalance를 처리하도록 한다.
k8s client 코드
from kubernetes import client, config
import os
def get_k8s_client():
if os.getenv('KUBERNETES_SERVICE_HOST'):
# Pod 내부에서 실행 중일 때
config.load_incluster_config()
else:
# 로컬 개발 환경
config.load_kube_config()
return client.CoreV1Api(), client.AppsV1Api()
- Pod에서 실행할 때는 ServiceAccount와 RBAC을 통해 k8s api를 사용할 수 있게 한다.
- Local일 경우에는 load kube config를 활용할 수 있도록 한다.
k8s_operation 코드
from kubernetes import client
import logging
from datetime import datetime
from .k8s_client import get_k8s_client
import asyncio
import json
logger = logging.getLogger(__name__)
class K8sOperations:
MAXIMUM_WAIT_PERIOD = 400
def __init__(self):
self.core_v1_api, self.apps_v1_api = get_k8s_client()
self.custom_objects_api = client.CustomObjectsApi()
async def get_node_labels(self, node_name: str):
node = self.core_v1_api.read_node(name=node_name)
return node.metadata.labels
async def cordon_node(self, node_name: str):
try:
body = {
"spec": {
"unschedulable": True
}
}
self.core_v1_api.patch_node(node_name, body)
logger.info(f"Node {node_name} cordoned successfully")
return True
except Exception as e:
logger.error(f"Failed to cordon node {node_name}: {str(e)}")
raise
async def get_targets(self, node_name: str):
targets = []
# 노드에서 실행 중인 파드를 필터링하기 위한 field_selector
field_selector = f'spec.nodeName={node_name}'
# 해당 노드의 모든 파드를 가져옵니다.
pods = self.core_v1_api.list_pod_for_all_namespaces(field_selector=field_selector)
for pod in pods.items:
for owner_reference in pod.metadata.owner_references:
# DaemonSet 파드는 제외
if owner_reference.kind == "DaemonSet":
break
else:
# Argo Rollout
if "rollouts-pod-template-hash" in pod.metadata.labels:
targets.append({
"name": pod.metadata.labels['app'],
"namespace": pod.metadata.namespace,
"kind": "Rollout"
})
elif pod.metadata.labels.get('strimzi.io/kind') == "KafkaConnect":
targets.append({
"name": pod.metadata.labels['app.kubernetes.io/instance'],
"namespace": pod.metadata.namespace,
"kind": "KafkaConnect"
})
elif owner_reference.kind == "ReplicaSet" and "app" in pod.metadata.labels:
name = pod.metadata.labels['app']
targets.append({
"name": name,
"namespace": pod.metadata.namespace,
"kind": "Deployment"
})
else:
logger.info(f"Unknown resource : {owner_reference.kind}, skipping")
return targets
async def restart_target(self, name: str, namespace: str, kind: str):
timestamp = datetime.now().strftime('%s')
body = {
"spec": {
"template": {
"metadata": {
"annotations": {
"kubectl.kubernetes.io/restartedAt": timestamp
}
}
}
}
}
try:
if kind == "Deployment":
self.apps_v1_api.patch_namespaced_deployment(name, namespace, body)
logger.info(f"Deployment {name} in namespace {namespace} restarted")
elif kind == "Rollout":
self.custom_objects_api.patch_namespaced_custom_object(
group="argoproj.io",
version="v1alpha1",
namespace=namespace,
plural="rollouts",
name=name,
body=body
)
logger.info(f"Rollout {name} in namespace {namespace} restarted")
elif kind == "KafkaConnect":
body = {
"spec": {
"template": {
"pod": {
"metadata": {
"annotations": {
"kubectl.kubernetes.io/restartedAt": timestamp
}
}
}
}
}
}
self.custom_objects_api.patch_namespaced_custom_object(
group="kafka.strimzi.io",
version="v1beta2",
namespace=namespace,
plural="kafkaconnects",
name=name,
body=body
)
logger.info(f"KafkaConnect {name} in namespace {namespace} restarted")
except Exception as e:
logger.error(f"Failed to restart {kind} {name}: {str(e)}")
raise
async def check_pods_moved(self, node_name: str):
pods = self.core_v1_api.list_pod_for_all_namespaces(
field_selector=f'spec.nodeName={node_name}'
)
# DaemonSet이 아닌 Running 상태의 Pod만 필터링
running_non_daemonset_pods = [
pod for pod in pods.items
if pod.status.phase == "Running" and
all(owner.kind != "DaemonSet" for owner in pod.metadata.owner_references or [])
]
return len(running_non_daemonset_pods) == 0
async def drain_and_delete_node(self, node_name: str):
try:
# Drain
body = {
"spec": {
"unschedulable": True,
"taints": [{
"effect": "NoSchedule",
"key": "drain",
"value": "true"
}]
}
}
# 1. drain node 수행
self.core_v1_api.patch_node(node_name, body)
# 2. delete node 수행
self.core_v1_api.delete_node(node_name)
logger.info(f"Node {node_name} drained and deleted successfully")
except Exception as e:
logger.error(f"Failed to drain and delete node {node_name}: {str(e)}")
raise
async def handle_rebalance(self, node_name: str):
try:
logger.info(f"Starting rebalance process for node: {node_name}")
# 1. node role 구하기
node_labels = await self.get_node_labels(node_name)
node_role = node_labels['role']
# 2. Cordon 수행
await self.cordon_node(node_name)
# 3. node에서 evict 해야할 target 구함 : Deployment, KafkaConnect, Rollout
targets = await self.get_targets(node_name)
logger.info(f"Found {len(targets)} targets on node {node_name}")
if len(targets) > 0:
# 4. target들을 evict
for target in targets:
name = target['name']
namespace = target['namespace']
kind = target['kind']
await self.restart_target(name, namespace, kind=kind)
# 시간 구하는 용도
start_time = datetime.now()
# MAXIMUM_WAIT_PERIOD 동안 대기하기
while True:
if await self.check_pods_moved(node_name):
logger.info(f"All pods successfully moved from node {node_name}")
# target이 아무것도 없거나 || while을 정상적으로 빠져나왔다면 drain & delete
await self.drain_and_delete_node(node_name)
logger.info(json.dumps({
"cluster": "MY_CLUSTER",
"duration": int((datetime.now() - start_time).total_seconds()),
"node_name": node_name,
"role": node_role,
"pod_count": len(targets),
"message": f"Node {node_name} has been successfully drained and deleted"
}))
break
if (datetime.now() - start_time).total_seconds() > K8sOperations.MAXIMUM_WAIT_PERIOD:
logger.info(f"Pods did not evicted from node '{node_name}' within the timeout period : {K8sOperations.MAXIMUM_WAIT_PERIOD}s. so, force drain and delete node")
# 제한시간이 초과되면 그냥 강제로 drain & delete
await self.drain_and_delete_node(node_name)
logger.info(json.dumps({
"cluster": "my-cluster",
"duration": int((datetime.now() - start_time).total_seconds()),
"node_name": node_name,
"role": node_role,
"pod_count": len(targets),
"message": f"Node {node_name} does not successfully drained and deleted within the timeout period : {K8sOperations.MAXIMUM_WAIT_PERIOD}s"
}))
break
await asyncio.sleep(5)
except Exception as e:
logger.error(f"Error in rebalance process for node {node_name}: {str(e)}")
이 부분이 중요한데 별거 처리하는건 없지만 크게 보면 다음과 같다.
1. node cordon 수행
2. node에 있는 Deployment, Rollout, KafkaConnect 리소스들을 판별한다.
3. Deployment, Rollout, KafkaConnect의 annotation에 restartedAt을 적용해준다.
https://kubernetes.io/docs/reference/labels-annotations-taints/#kubectl-k8s-io-restart-at
Well-Known Labels, Annotations and Taints
Kubernetes reserves all labels and annotations in the kubernetes.io and k8s.io namespaces. This document serves both as a reference to the values and as a coordination point for assigning values. Labels, annotations and taints used on API objects apf.kuber
kubernetes.io
kubectl rollout restart <RESOURCE>를 수행해주는 역할을 하는데 Pod가 1대일 경우 기존 파드는 살려두고 새로운 파드가 뜬 것을 확인하고 나서야 기존 파드를 죽이는 역할을 수행한다.
이 부분이 매우 중요한데 이것 때문에 Custom API를 만들게 된 것이다.
4. node에 떠있는 Deployment, Rollout, KafkaConnect 개수가 0개인지 아닌지 체크하고 0개일 경우 drain, delete를 수행한다.
5. 최대시간(MAXIMUM_WAIT)을 400초로 설정했는데 이 시간을 넘어서면 강제로 cordon, drain을 수행한다.
위 과정을 통해 기존보다 좀 더 안전하게 스팟 인스턴스를 활용할 수 있게 되었고, 개발자들은 예상치 못한 API 다운타임을 최소화할 수 있게 되었다.
물론 이렇게 적용하는 것이 최선의 방법은 아니겠지만 그래도 어느정도 스팟 인스턴스를 좀 더 활용할 수 있도록 하는데 도움이 되지 않을까 생각해본다.
'DevOps' 카테고리의 다른 글
| [DevOps] EKS 환경에서 Helm으로 Jenkins 안전하게 구축하기 (3) | 2024.12.10 |
|---|---|
| [Harbor] EKS 환경에서 Harbor 고가용성(HA)으로 구성하기 (2) | 2024.06.08 |
| [Grafana Loki] 청크 중복성 제거하기 (ingester에만 chunk cache 적용) (0) | 2024.05.10 |
| [Strimzi Kafka Connect] 손쉽게 커넥터 Config에 시크릿 적용하기 (0) | 2024.05.01 |
| [Ansible] 사용자 계정 생성 및 apache http 설치 실습 (0) | 2024.02.04 |



