(조대협님 블로그글 참고하여 작성)
데이터 및 로그 수집 플랫폼으로 EFK, ELK 스택이 많이 사용되고 있다.
EFK는 Elasticsearch, Fluentd, Kibana를 의미하며
ELK는 Elasticsearch, Logstash, Kibana를 의미한다.
Logstash는 아키텍처 적응에 대한 유연성와 연동 솔루션에 대한 호환성을 강조하고 있기 때문에 타 솔루션과 연동이 강하고, Fluentd는 아키텍처의 단순성과 이를 기반으로 하는 안정성을 초점에 두고 있다.
Fluentd를 이용한 로그 수집 아키텍처
[1] 기동되고 있는 서버에서 로그를 수집하고 중앙 로그 저장소로 전송
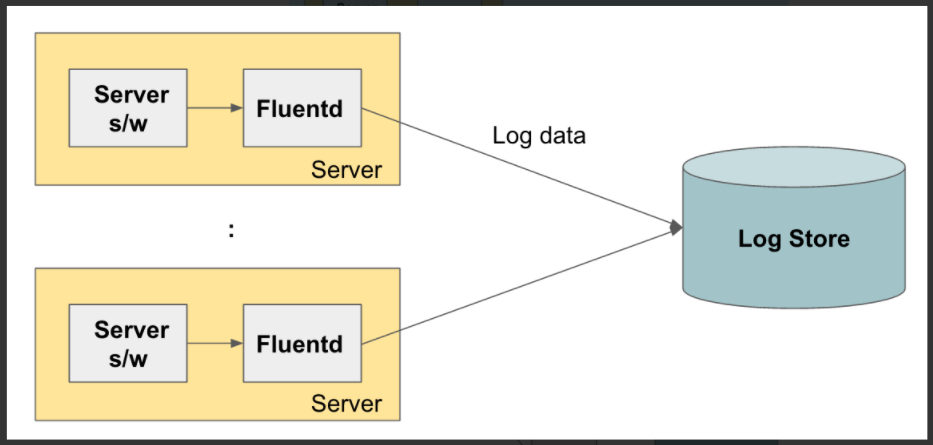
[2] 각 서버에서 Fluentd가 수집한 로그를 다른 Fluentd로 보내서 이 Fluentd가 최종적으로 로그 저장소에 저장
: fluent가 앞에서 들어오는 로그들을 수집해서 로그 저장소에 넣기 전에 로그 트래픽을 Throttling(속도 조절)을 해서 로그 저장소의 용량에 맞게 트래픽을 조정 가능하도록 하기 위해

[3] 로그를 여러 개의 저장소에 복제해서 저장하고나 로그의 종류에 따라서 각각 다른 로그 저장소로 라우팅

Fluentd 내부 구조
Input, Parser, Engine, Filter, Buffer, Output, Formatter 7개의 컴포넌트로 구성
일반적인 흐름은 Input → Engine → Output이고,
Parser, Buffer, Filter, Formatter 등을 설정에 따라 선택적으로 추가 또는 삭제 가능

1. Input
로그를 수집하는 플러그인으로, 다양한 로그 소스를 지원한다.
다양한 서버나 애플리케이션으로 부터 다양한 포맷의 데이터를 수집할 수 있다.
2. Parser (Optional)
Input 플러그인을 통해서 들어온 데이터를 읽어도 데이터 포맷이 Fluentd에서 지원하지 않는 데이터 포맷인 경우가 있기 때문에 이를 파싱하기 위해 Parser 플러그인을 선택적으로 사용할 수 있다.
(Regular Expression, Apache, Nginx, Syslog, ..)
3. Filter (Optional)
Filter 플러그인을 읽어들인 데이터를 Output으로 보내기 전에, 다음과 같은 3가지 기능을 한다.
- 필터링
- 데이터 필드 추가
- 데이터 필드 삭제 또는 특정 필드 마스킹
필터링은 특정 데이터만 Output 필드로 보내고 나머지는 버리도록 한다.
ex) 로그 데이터에 seoul이란 문자열이 있는 경우만 로그 서버로 보내거나 error, warning과 같은 특정 패턴이 있을 경우에만 로그 저장소로 보낼 수 있도록 한다.
4. Output
앞에서 필터링된 데이터를 데이터 저장 솔루션에 데이터를 저장하도록 한다 (S3, ES, Big Query, ..)
5. Formatter (Optional)
Output 플러그인을 통해 데이터를 저장소에 쓸 때, Formatter를 이용하면 데이터의 포맷을 정의할 수 있다.
ex) Input의 parser가 포맷에 맞게 읽는 플러그인이라면, Formatter는 Output을 위한 포맷을 지정하는 플러그인)
6. Buffer (Optional)
Input에서 들어온 데이터를 바로 Output으로 보내서 쓰는 것이 아니라 중간에 선택적으로 Buffer를 둬서 Throttling을 할 수 있다.
버퍼는 File과 Memory 2가지를 사용할 수 있다.
[Buffer 구조와 동작 원리]

Buffer에는 로그 데이터를 분리하는 Tag 단위로 Chunk가 생성이 된다.
Chunk에 데이터가 쌓여서 buffer_chunk_limit만큼 Chunk가 쌓여서 full이 되거나, 설정값에 의해 정의된 flush_interval 주기가 되면 로그 저장소로 로그를 쓰기 위해서 Queue에 전달이 된다.

다음 Queue에서는 데이터를 읽어서 로그 저장소에 데이터를 쓰는데, 로그 저장소에 문제가 없다면 바로 로그가 써지겠지만 네트워크 에러나 로그 저장소 에러로 로그를 쓰지 못할 경우에는 retry_wait 시간 만큼 대기를 한 후에 다시 쓰기를 시도한다.
만약에 Queue가 차버렸을 때 처리에 대한 정책을 설정할 수 있는데, “exception”과 “block” 모드 2가지가 있다.
Exception 모드일 경우에는 BufferQueueLimitError를 내도록 하고,
Block 모드의 경우 BufferQueueLimitError가 해결될 때까지 Input Plugin을 중지 시킨다. (로그 수집 X)
Queue가 차버렸을 때 다른 처리 방법으로는 큐가 다 찼을 때, Secondary output을 지정해서, 다른 로그 저장소에 로그를 저장하는 방법이 있을 수 있다.
ex) secondary output을 AWS S3로 지정해 놓고, S3로 로그를 일단 저장하게 하고 나중에 mongodb가 복구된 후에, S3에서 다시 mongodb로 로그를 수집하는 방식을 취할 수 있다.

데이터 구조
Fluentd가 내부적으로 어떻게 로그 데이터를 핸들링하는지 데이터 구조를 확인해보자.

데이터는 크게 3가지 파트로 구성이 된다.
Time : 로그데이터의 생성 시간
Record : 로그 데이터의 내용으로 JSON 형태로 정의
Tag : 데이터의 분류이다. 로그 레코드는 tag를 통해 로그의 종류가 정해지는데, 이 tag에 따라서 로그에 대한 필터링, 라우팅과 같은 플러그인이 적용이 된다.
Example
/etc/td-agent/td-agent.conf
<ROOT>
<match td.*.*>
type tdlog
apikey xxxxxx
auto_create_table
buffer_type file
buffer_path /var/log/td-agent/buffer/td
<secondary>
type file
path /var/log/td-agent/failed_records
buffer_path /var/log/td-agent/failed_records.*
</secondary>
</match>
<match debug.**>
type stdout
</match>
<source>
type forward
</source>
<source>
type http
port 8888
</source>
<source>
type debug_agent
bind 127.0.0.1
port 24230
</source>
</ROOT>
Ref : https://bcho.tistory.com/1115
https://jonnung.dev/system/2018/04/06/fluentd-log-collector-part1/
'Log,Monitorings' 카테고리의 다른 글
| [EKS] 아주 가벼운 Loki + Grafana + Promtail 로그 시스템 구성 (2) | 2022.10.31 |
|---|---|
| [Datadog] EKS에서 운영중인 SpringBoot HikarpCP 모니터링 (Auto Discovery) (0) | 2022.09.09 |
| [Datadog] AWS Events 기반으로 Datadog 알람 설정하기 (0) | 2022.06.26 |
| [Elasticsearch] Nginx 로그 Fluentd를 통해 Elasticsearch로 보내기 (0) | 2021.12.20 |
| [ElasticSearch] ElasticSearch 개념 알아보기 (0) | 2021.11.11 |



