Opentelemetry Collector로부터 Trace를 수집받은 뒤 RED Metrics를 만드는 방법에 대해서 알고 싶다면?
[Spanmetrics에 대한 설명]
https://nyyang.tistory.com/190
[Opentelemetry] spanmetrics connector에 대해 알아보기
Span Metrics Connector는 span data로부터 RED(Request, Error, Duration) 메트릭을 만들어낸다. 생성되는 메트릭들은 다음의 dimension들을 최소한 가지게 된다. - service.name - span.name - span.kind - status.code 1. 설정값 hi
nyyang.tistory.com
[RED Metrics를 Opentelemetry Collector로 생성하는 방법,
최근에 사용하는 설정과는 조금 달라졌지만
실제 실무에서 큰 이슈 없이 사용하고 있어요.
]
https://nyyang.tistory.com/193
[Opentelemetry Collector] RED Metric 생성과 샘플링 정책 완벽히 구성하기
1. 개요필자의 경우 Grafana Tempo를 사용하고 있다. Grafana Tempo의 경우 Metrics Generator를 통해 RED Metric을 생성할 것을 권장하고 있다. Metrics-generator | Grafana Tempo documentationOpen source Metrics-generator Metrics-gen
nyyang.tistory.com
1. 기존 모니터링 시스템의 한계
전통적인 모니터링 시스템은 서버 엔지니어가 서버를 주기적으로 점검하고 CPU 사용량, 메모리 사용량, 디스크 I/O, 네트워크 트래픽 등 기본적인 인프라 지표를 수집하여 문제가 발생할 가능성을 예측하거나, 이미 발생한 문제를 감지하는 데 유용했습니다.
그러나 기존의 이러한 지표들이 비교적 단순한 형태의 문제 해결에 적합했지만, 마이크로서비스 아키텍처로 전환함에 따라 이들 전통적인 모니터링 시스템의 한계가 드러나기 시작했습니다.
첫째, 기존 모니터링 시스템은 각 마이크로서비스로 운영되는 환경에서 전체적인 시스템 상태를 종합적으로 이해하기 어렵게 만듭니다. 이슈가 발생할 경우 각 마이크로서비스 간의 연관성을 파악하는 데 어려움이 있으며 문제의 근본 원인을 찾기가 쉽지 않습니다.
둘째, 기존의 모니터링 도구들은 주로 사후 대응적인 접근을 취합니다. 이는 문제가 이미 발생한 후에야 지표를 통해 이상을 감지하기 때문에 빠른 대응이 필요한 복잡한 시스템에서는 충분히 효과적이지 않습니다.
셋째, 로그와 같은 데이터는 시스템에서 발생하는 모든 이벤트를 기록하는 데 유용하지만, 각 마이크로서비스 간 연관성이나 이벤트 흐름을 추적하는 데 충분한 정보를 제공하지 못했습니다.
마이크로서비스 환경이 급부상하게 되면서 이런 문제들이 여럿 제기되었고 그 때 관찰 가능성이란 개념이 나타나게 되었습니다.
갑자기 특정 서비스에서 다음의 이슈들이 발생했다고 가정해보겠습니다.
- 신규 버전을 배포했는데 갑자기 다른 서비스들까지 에러가 발생하고 응답 시간이 느려짐
- 애플리케이션에는 아무런 이상이 없는데 처리량이 갑자기 느려짐
- 갑자기 DB 부하가 치솟는데 어떤 애플리케이션에서 원인을 발생하는지 알 수 없음
마이크로서비스 아키텍처가 점점 발전하면서 단일 애플리케이션을 여러개의 작은 서비스들로 쪼개는 것이 더욱 쉬워졌습니다. 하지만 이로 인해 비즈니스 로직의 복잡성이 증가하고, 연동해야 할 솔루션과 데이터베이스의 수 또한 늘어나게 되었습니다. 이러한 상황에서 이슈가 발생하면 어떤 원인으로 이슈가 발생했는지 파악하는것은 쉽지 않습니다.
각 마이크로서비스가 어떤 패턴으로 동작하는지, 외부에서 측정되는 지표는 무엇인지, 시스템 내부 상태는 어떤지 등을 정확히 파악하는 것이 중요해졌습니다. 즉, 시스템의 복잡도 및 운영 난이도가 상승함에 따라 메트릭들, 애플리케이션 로그, 애플리케이션 성능 지표, Git 등 다양한 종속성과 버저닝까지 충분한 정보가 있어야 하고 상호 연동이 되어 있어야 합니다.
관찰 가능성(Observability)의 목표는 단순히 문제를 감지하는 모니터링을 넘어, 문제가 어디에서 발생했는지, 그리고 그 원인이 무엇인지 빠르게 이해할 수 있도록 돕는 것입니다. 이를 가능하게 하는 핵심 요소 3가지는 메트릭(Metrics), 로그(Logs), 그리고 트레이스(Traces)입니다.
2. Opentelemetry가 왜 등장하게 되었고, Opentelemetry가 무엇인가?
개발자, 시스템 운영자 등은 본인이 운영하는 애플리케이션의 성능과 상태를 안정적으로 운영해야 하는 책임이 있습니다. 애플리케이션의 응답 속도가 정상인지, 에러는 발생하지 않는지, 의도한 대로 작동하는지 등을 파악하고 있어야 하는데요.
이 때 애플리케이션의 현재 상태에 대한 정보를 수집하기 위해 애플리케이션 내에 agent를 배포하여 수집하고 원격 데이터 저장소로 보내는 과정이 필요하게 됩니다.
옛날에는 애플리케이션에 대한 메트릭, 로그, 트레이스 등을 각각 agent를 설치하여 수집하고 가공 후 원격 데이터 저장소로 보내야 하는 불편함이 있었습니다. 예를 들어 ElasticAPM에서 Trace를 수집하기 위해서 애플리케이션에서는 elastic agent를 삽입해야하고 이후 Pinpoint로 Trace 수집 도구를 변경해야 한다면 또 별도로 agent를 삽입하는 등 특정 벤더사의 기술에 얽매이게 되는 단점이 존재했습니다.
Opentelemetry는 이러한 문제를 해결하기 위해 나타났으며 애플리케이션에서 발생하는 데이터를 Opentelemetry라는 단일 개방형 표준으로 수집할 수 있도록 해줍니다.
즉, OpenTelemetry는 CNCF에서 개발하고 있으며 원격 측정 데이터를 생성, 처리 및 전송할 수 있도록 하는 오픈 소스 Observability 프레임워크이며 특정 벤더에 얽매이지 않도록 하며 Opentelemetry를 통해 우리는 원격 데이터 저장소를 자유롭게 변경할 수 있게 되었습니다.
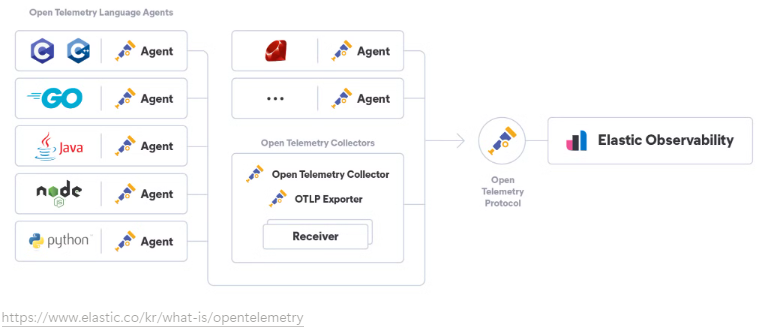
Opentelemetry는 측정 데이터를 수집하여 원하는 Observability 백엔드로 보낼 수 있는 표준 프레임워크를 제공합니다.
즉, Opentelemetry agent를 구성해두면 추후 LGTM Stack이든 Elastic Observability든 원하는 백엔드 수집 저장소로 언제든지 변경할 수 있음을 의미하게 됩니다.
일반적인 구성은 다음과 같습니다.
[1] 언어별 Opentelemetry SDK, API, Agent 등을 활용해 텔레메트리 데이터를 수집하고 Opentelemetry Collector로 보냅니다.
일반적으로 Opentelemetry의 자동 계측(Auto-Instrumentation)을 활용하여 소스 코드를 변경하지 않고 자동으로 애플리케이션을 계측할 수 있도록 설정합니다.
[2] Opentelemetry Collector에서 수집하고 데이터를 원하는 대로 가공한 뒤 Observability 백엔드로 전송합니다.
Opentelemetry agent에서 계측한 데이터를 중앙 Opentelemetry Collector로 보냅니다. 그 후, Opentelemetry Collector에서는 불필요한 데이터를 제거하고 필요한 데이터를 추가하거나 Trace를 시계열 메트릭으로 변환하거나 등 가공 단계를 거치고 실제 Observability 백엔드로 전송하게 됩니다.
### 2.2.1. Opentelemetry Collector에 대해서 알아보기
Opentelemetry Collector는 Opentelemetry Agent 뿐 만 아니라 Prometheus, FluentBit, File, HTTP 등 여러가지의 Source 로부터 데이터를 전달받고 가공한 뒤 Export(내보내기)를 프록시입니다.
Opentelemetry Collector의 구성 요소로는 다음과 같습니다.
Opentelemetry Collector에 대해서 알아보기
Opentelemetry Collector는 Opentelemetry Agent 뿐 만 아니라 Prometheus, FluentBit, File, HTTP 등 여러가지의 Source 로부터 데이터를 전달받고 가공한 뒤 Export(내보내기)를 프록시입니다.
Opentelemetry Collector의 구성 요소로는 다음과 같습니다.
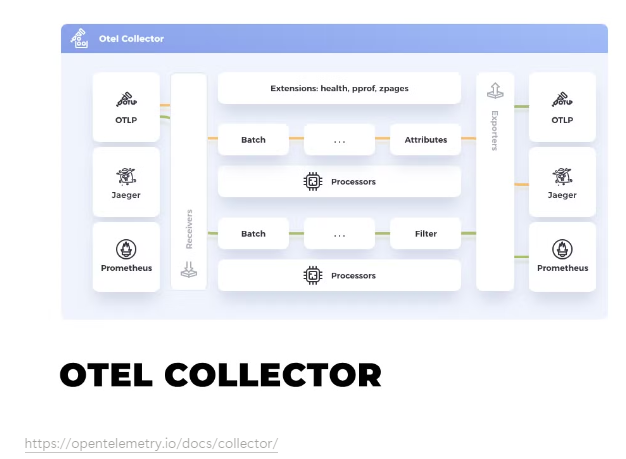
[1] Receivers(수신기) : 수신기는 telemetry data를 수집하는 컴포넌트입니다.
Pull(Opentelemetry Collector가 직접 긁어오는 방식)일 수도 있고 Push(외부에서 Opentelemetry Collector에게 전송하는 방식)일 수도 있습니다.
어찌 되었든 목적은 Opentelemetry Collector가 데이터를 수집하는 것입니다.
아래는 Receivers 예시입니다.
receivers:
# Data sources: logs
fluentforward:
endpoint: 0.0.0.0:8006
# Data sources: metrics
hostmetrics:
scrapers:
cpu:
# Data sources: traces
jaeger:
protocols:
grpc:
endpoint: 0.0.0.0:4317
# Data sources: traces, metrics, logs
kafka:
protocol_version: 2.0.0
# Data sources: traces, metrics
opencensus:
# Data sources: traces, metrics, logs
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
# Data sources: metrics
prometheus:
config:
scrape_configs:
- job_name: otel-collector
scrape_interval: 5s
static_configs:
- targets: [localhost:8888]
[2] Processors : Processors는 telemetry data를 Exporter로 보내기 전 가공하기 위한 컴포넌트입니다.
데이터가 들어올 경우 필터링을 하거나 데이터를 아예 삭제해버리거나 데이터를 수정하는 작업을 수행하기 됩니다. 즉, 데이터 가공이 주 목적입니다.
아래 예시를 보면 processors에서 어떤 작업들을 수행할 수 있는지 확인할 수 있습니다.
- attribute를 추가하거나 삭제하거나 hash
- 특정 메트릭을 filtering
- opentelemetry collector 프로세스 자체에 대한 메모리 관리를 위한 memory_limiter
- trace sampling을 수행해서 비용 효율적으로 데이터를 observability backend로 보내기
processors:
# Data sources: traces
attributes:
actions:
- key: environment
value: production
action: insert
- key: db.statement
action: delete
- key: email
action: hash
# Data sources: traces, metrics, logs
batch:
# Data sources: metrics
filter:
metrics:
include:
match_type: regexp
metric_names:
- prefix/.*
- prefix_.*
# Data sources: traces, metrics, logs
memory_limiter:
check_interval: 5s
limit_mib: 4000
spike_limit_mib: 500
# Data sources: traces
resource:
attributes:
- key: cloud.zone
value: zone-1
action: upsert
- key: k8s.cluster.name
from_attribute: k8s-cluster
action: insert
- key: redundant-attribute
action: delete
# Data sources: traces
probabilistic_sampler:
hash_seed: 22
sampling_percentage: 15
# Data sources: traces
span:
name:
to_attributes:
rules:
- ^\\/api\\/v1\\/document\\/(?P<documentId>.*)\\/update$
from_attributes: [db.svc, operation]
separator: '::'
[3] Exporters : Exporters는 수집 → 가공 된 데이터를 최종적으로 백엔드로 보내기 위한 컴포넌트입니다.
백엔드로 보내기 위해서는 인증 정보(id, password)가 필요하거나 Bearer Token이 필요하거나 tls key file이 필요할 수도 있고 queue가 필요할 수도 있습니다. Exporters에서는 이런 작업들을 수행하게 됩니다.
아래 exporters 예시를 보면 file로 출력할 수도 있고 jaeger로 보내거나 kafka로 보내거나 otlp endpoint로 보내거나 등 작업을 수행할 수 있게 됩니다.
exporters:
# Data sources: traces, metrics, logs
file:
path: ./filename.json
# Data sources: traces
otlp/jaeger:
endpoint: jaeger-server:4317
tls:
cert_file: cert.pem
key_file: cert-key.pem
# Data sources: traces, metrics, logs
kafka:
protocol_version: 2.0.0
# Data sources: traces, metrics, logs
# NOTE: Prior to v0.86.0 use `logging` instead of `debug`
debug:
verbosity: detailed
# Data sources: traces, metrics
opencensus:
endpoint: otelcol2:55678
# Data sources: traces, metrics, logs
otlp:
endpoint: otelcol2:4317
tls:
cert_file: cert.pem
key_file: cert-key.pem
# Data sources: traces, metrics
otlphttp:
endpoint: <https://otlp.example.com:4318>
# Data sources: metrics
prometheus:
endpoint: 0.0.0.0:8889
namespace: default
# Data sources: metrics
prometheusremotewrite:
endpoint: <http://prometheus.example.com:9411/api/prom/push>
# When using the official Prometheus (running via Docker)
# endpoint: '', add:
# tls:
# insecure: true
# Data sources: traces
zipkin:
endpoint: <http://zipkin.example.com:9411/api/v2/spans>
[4] Connectors : 커넥터는 2개의 파이프라인을 이어주는 역할을 하게 됩니다. 즉, Exporter와 Receiver를 이어주게 됩니다.
아래 예시를 보면 금방 이해하실 수 있습니다.
foo라는 trace receiver로부터 데이터를 수집하게 되고 count라는 connector를 활용해서 span events 개수를 측정하게 됩니다.
이제 수집된 span events 개수는 traces가 아니라 metrics pipeline 내 bar라는 exporter로 전달되어야 하기 때문에 connector가 활용되게 됩니다.
receivers:
foo:
exporters:
bar:
connectors:
count:
spanevents:
my.prod.event.count:
description: The number of span events from my prod environment.
conditions:
- 'attributes["env"] == "prod"'
- 'name == "prodevent"'
service:
pipelines:
traces:
receivers: [foo]
exporters: [count]
metrics:
receivers: [count]
exporters: [bar]
3. 정리
앞으로 모든 Observability 생태계는 Opentelemetry로 돌아갈 것입니다.
사용 방법도 매우 쉽고 특정 Vendor에 종속되는게 아니며, Jaeger 같은 백엔드 수집 저장소도 앞으로 V2(Version 2)에서는 Opentelemetry를 활용하는 방향으로 바꾸고 있다고 합니다.
따라서 Opentelemetry의 사용은 필수 필수 불가결입니다.
이번 글은 간단히 Opentelemetry가 무엇인지만 다루었으며 다음에는 더 좋은 컨텐츠를 가지고 오겠습니다.
'Log,Monitorings' 카테고리의 다른 글
| [ECK Elasticsearch] 데이터 노드가 재시작되면 레이턴시가 급증했던 이슈 (2) | 2024.12.05 |
|---|---|
| [Monitoring] Grafana Query-less (Explore Metrics, Logs, Traces, Profiles) 간단히 알아 (0) | 2024.07.21 |
| [Log] Grafana Loki 성능 최적화 방법 정리 (0) | 2024.04.07 |
| [Opentelemetry Collector] RED Metric 생성과 샘플링 정책 완벽히 구성하기 (10) | 2024.03.19 |
| [Log] Grafana Loki 로그 Write 시 참고 사항 (3) | 2024.02.17 |



